Caramelo: Teaching a Small Language Model to Write in One Person's Voice Without Breaking Its Reasoning
Guilherme Favaron · Technical report, 25 June 2026 · ia-caramelo.com · huggingface.co/guifav/caramelo
Abstract
We document the construction and evaluation of Caramelo, a personal-voice assistant built by fine-tuning google/gemma-3-4b-it with a Low-Rank Adaptation (LoRA) trained on the writing of a single author. The first attempt regressed: trained on raw article pairs, the adapter learned the format of an article rather than how to answer, and lost a blind A/B comparison against the base model (21% style, 15% quality). We diagnose this as a data-format bias and correct it with a style-correction dataset: diverse prompts are answered by the base model, the drafts are rewritten in the author's voice by parallel LLM subagents anchored to real excerpts, and the targets are filtered by objective style markers before training. The second adapter (named caramelo 3.4.2) reverses the result, winning the same blind comparison on style (91 to 100 percent across two judges) and quality (66 to 70 percent). We then measure capability along two further axes the style score cannot see. Reasoning, measured on 1,432 ENEM multiple-choice questions, is preserved (57.2 to 57.5 percent). General conversational helpfulness, measured on a two-turn Portuguese MT-Bench-style set, regresses under an aggressively concise persona (12 to 25 percent) because the model over-trims substantive answers, and is recovered to parity or better (41 to 62 percent) by a single completeness instruction in the system prompt, with no retraining. We argue that the three axes move independently, that the format of training data is the primary lever for a small style fine-tune, and that an evaluation gate built before training is what separates a shipped improvement from a shipped regression.
1. Introduction
A growing number of teams want a language model that sounds like them: a company's support voice, an author's prose, a product's tone. The cheap and popular path is to take a small open model and fine-tune a LoRA on in-house text. This report is a careful account of doing exactly that for one author's writing, including the part most case studies omit: the first version came out measurably worse than the model it started from.
The contribution is not a new method. LoRA, QLoRA, and LLM-as-judge evaluation are all established. The contribution is a thorough, reproducible end-to-end case study that isolates three findings practitioners repeatedly rediscover the hard way:
- For a small style fine-tune, the format of the training data is what the model learns, before and above its content.
- A style score is not a capability score. Voice, reasoning, and general helpfulness move independently and must be measured separately.
- A regression that looks like a training problem (the model is "too terse to be useful") can be a prompting problem, fixable without touching the weights.
We organize the report as a narrative of two attempts. Section 3 describes the failed first attempt and its diagnosis. Section 4 describes the style-correction pipeline that fixed it. Section 5 defines the evaluation protocol, Section 6 reports results across three axes, and Sections 7 and 8 discuss lessons and limitations.
2. Background
LoRA and QLoRA. Low-Rank Adaptation (Hu et al., 2021) freezes the base weights and trains a small pair of low-rank matrices injected into selected projections, so that only a few million parameters are updated. QLoRA (Dettmers et al., 2023) adds 4-bit NF4 quantization of the frozen base, making it possible to fine-tune a multi-billion-parameter model on a single commodity GPU. Both are designed to change behavior cheaply, not to add knowledge.
Style fine-tuning and catastrophic forgetting. Adapting a model on a narrow corpus risks catastrophic forgetting (McCloskey and Cohen, 1989; Goodfellow et al., 2013): the model acquires the target distribution and loses competence acquired during pretraining. For a 4-billion-parameter model fine-tuned on a few hundred examples, this is a concrete risk, not a theoretical one, and it motivates measuring reasoning before and after.
LLM-as-judge and MT-Bench. Pairwise preference judged by a strong model correlates well with human preference (Zheng et al., 2023, MT-Bench and Chatbot Arena) and is the practical way to score open-ended quality at low cost. The known failure modes are position bias and verbosity bias, which we mitigate with blind randomized ordering and, for capability, by judging usefulness rather than style.
The base model. Caramelo is built on google/gemma-3-4b-it, the 4-billion-parameter instruction-tuned variant of Gemma 3 (Google DeepMind, 2025), chosen because it is open, small enough to serve on commodity hardware, and competent in Portuguese.
3. The First Attempt and Its Failure (v1)
The author's corpus is roughly 229 long-form essays from a Portuguese newsletter. The intuitive first dataset paired an instruction of the form "write an article about X" with the corresponding essay as the target. This is a faithful representation of the author's prose, and it is the wrong thing to teach.
A model does not learn what you intend; it learns what you show, repeatedly. What this dataset showed, in every example, was the shape of an article beginning. The resulting adapter (retroactively named caramelo 3.4.1) answered arbitrary questions as if opening an essay: ask it the time and it returns a title and an introductory paragraph.
We measured this with a paired blind A/B test (protocol in Section 5.1): the same held-out prompts were answered by the base model and by the base-plus-v1 adapter under an identical persona and sampling configuration, and two model judges chose the better answer without knowing which was which. The v1 adapter won on style only 21% of the time and on overall quality only 15%. The base model it started from was better. We had spent compute to make the model worse.
The diagnosis, confirmed by objective markers, was format bias: the v1 outputs had longer, throat-clearing openings and reproduced the article structure instead of answering. The fix is not more data or more parameters. It is changing what the model is shown.
4. Method: A Style-Correction Dataset (v2)
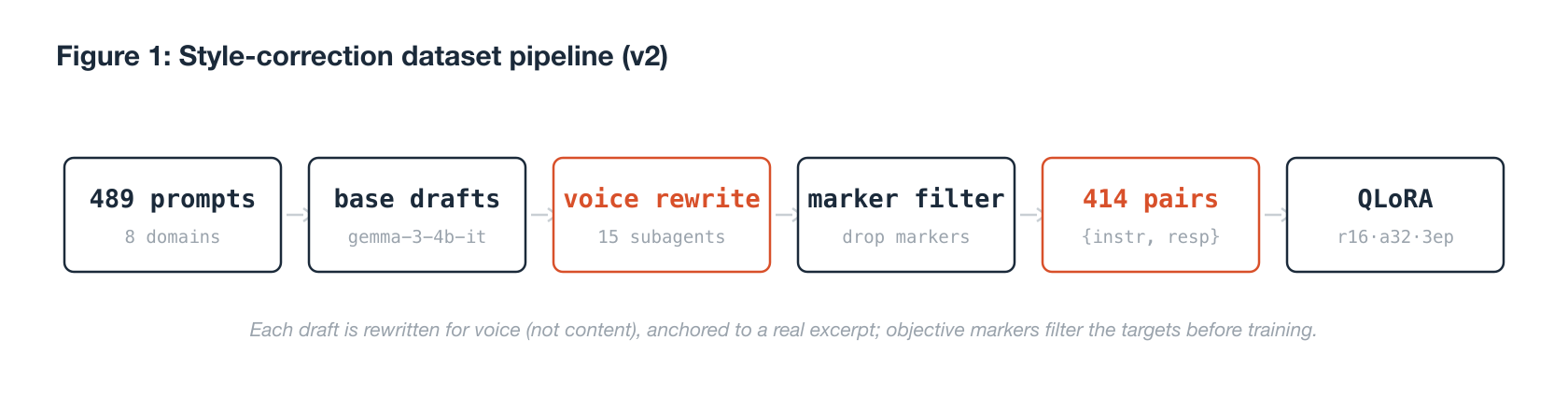
The corrected approach builds a conversational dataset whose training pairs match the inference task, {prompt, answer}, so the model learns to answer in the voice rather than to imitate a document format. The dataset is constructed in five stages.
(1) Prompt generation. We generate 489 diverse prompts across eight domains (growth, career, technical explanation, opinion, summarization, and others), of the kind a user would actually send to an assistant. Prompts are produced with an auxiliary model (GLM-5.2).
(2) Base drafts. The unmodified gemma-3-4b-it answers each prompt, producing a generic, neutral draft. This draft is the raw material for the rewrite, not the final target. Generation is batched with left-padding (batch size 16) after a single-sequence pass proved too slow (175 of 489 items in 60 minutes), which cut wall-clock time roughly tenfold.
(3) Voice rewriting by subagents. Each draft is rewritten in the author's voice by 15 parallel Claude (Sonnet) subagents, each handling a batch and guided by an explicit style rubric (RUBRIC.md). Crucially, each rewrite is anchored to a real excerpt from the author's essays, supplied as a reference for voice, not content: the instruction is to capture the manner, not to copy the text. Using one AI to teach another AI to write like a specific human is the practical core of the method; the human work is defining the style, choosing the anchor excerpts, and building the filter.
(4) Validation and style filtering. Subagent outputs are parsed and validated as JSON (482 of 489 survived; 7 failed on escaping in long responses and were dropped). The valid targets then pass an objective marker filter (markers.py) that discards any answer containing the author's documented anti-patterns: marketing hype, the negation-correction tic ("not X, but Y"), emoji, an over-long opening, or article-format structure. Garbage in the target is garbage in the adapter, so the filter operates on the data itself rather than trusting the rewrite.
(5) Training. The surviving 414 {instruction, response} pairs are used to train a QLoRA adapter on the 4-bit NF4 base. Configuration: rank 16, alpha 32, dropout 0.05, learning rate 2e-4 with 0.03 warmup ratio, three epochs, per-device batch size 4 with gradient accumulation 4 (effective batch 16), maximum sequence length 2048. Training takes about ten minutes on a single L4 GPU at roughly 12 GB peak memory, reaching a final training loss near 1.58. The result is published as guifav/caramelo-lora-adapter-v2 and merged into guifav/caramelo, named caramelo 3.4.2 under the scheme caramelo {Gemma-generation}.{size-in-B}.{iteration}.
5. Evaluation Protocol
We evaluate along three axes with three separate instruments. All comparisons are between the base model and the v2 adapter under the same server-side persona and sampling, so the adapter is the only variable.
5.1 Style and quality (blind A/B preference)
Twenty-four held-out prompts (disjoint from training) are answered by both models. Two judges, GLM-5.2 and the Codex CLI, see each pair in randomized order without knowing which answer belongs to which model, and choose the better one for style and for overall quality separately. The promotion rule is a hard gate: the new version is promoted only if it beats the base. This same gate is what caught the v1 regression.
5.2 Objective style markers
Independent of judges, we count five objective markers per answer: occurrences of the negation-correction construction, hype phrases, emoji, words per response, and the length of the first sentence. These are deterministic and serve as an audit of the preference scores.
5.3 Reasoning (ENEM)
To detect catastrophic forgetting we use the ENEM, the Brazilian national exam, as a Portuguese reasoning and knowledge benchmark. We score 1,432 non-annulled multiple-choice questions zero-shot, selecting the answer by the log-likelihood of the final-token letter (A to E), with left-padding and left-side truncation. This isolates reasoning from generation style.
5.4 Conversation (MT-Bench-PT)
To measure general helpfulness in dialogue we use a custom MT-Bench-style set of 24 two-turn conversations across eight categories (coding, math, extraction, reasoning, writing, and others), judged blind and randomized by GLM-5.2 and Codex on usefulness, with style set aside. We run two persona variants to separate the effect of the adapter from the effect of the prompt (Section 6.3).
6. Results
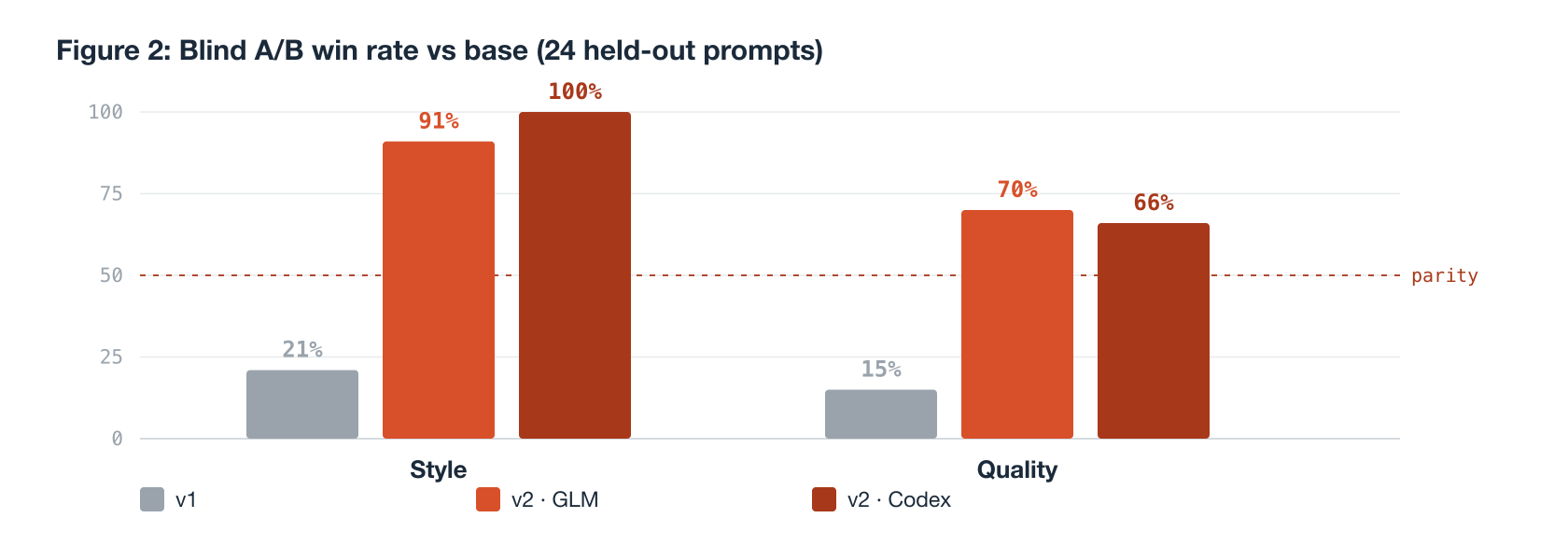
6.1 Style and quality
The v2 adapter reverses the v1 result decisively.
| Judge | Style (v2 win) | Quality (v2 win) |
|---|---|---|
| GLM-5.2 | 91% (22/24) | 70% (17/24) |
| Codex (CLI) | 100% (24/24) | 66% (16/24) |
| v1, for contrast | 21% | 15% |
The objective markers corroborate the preference. The v2 answers carry none of the author's anti-patterns and are shorter overall, while opening with a longer but substantive first sentence rather than filler.
| Model | neg-correction | hype | emoji | words/resp | 1st sentence |
|---|---|---|---|---|---|
| base | 1 | 2 | 0 | 263.6 | 6.5 |
| v2 | 0 | 0 | 0 | 195.6 | 13.5 |
6.2 Reasoning is preserved
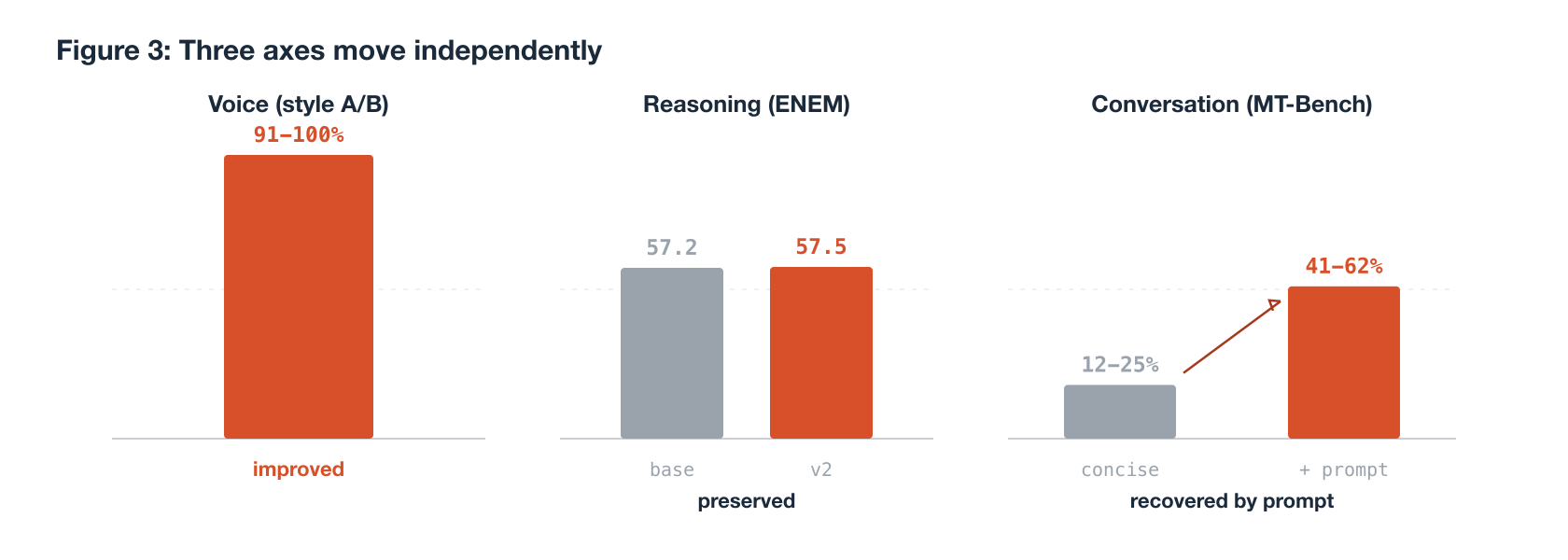
The style fine-tune does not move reasoning. On 1,432 ENEM questions the base scores 57.2% and the v2 adapter 57.5%, a difference of 0.3 points that is a statistical tie.
| Model | ENEM accuracy (n=1432) |
|---|---|
| Gemma 3 4B base | 57.2% |
| caramelo 3.4.2 | 57.5% |
This is the intended outcome. A 414-example, low-rank style adapter is not expected to make the model smarter, and the work here was to confirm it does not make the model worse at reasoning. For a model whose reason to exist is tone, with knowledge inherited entirely from the base, this tie is the best available result.
6.3 Conversation: a concision tradeoff, and its mitigation
The third axis complicates the picture. Judged on usefulness across diverse two-turn tasks, the v2 adapter under an aggressively concise persona loses to the base.
| Judge | Win | Tie | Loss | v2 win rate |
|---|---|---|---|---|
| GLM | 3 | 15 | 6 | 12% |
| Codex | 6 | 16 | 2 | 25% |
The cause is visible in the first sample. Asked to solve a linear equation step by step, the base produces 342 characters of explanation and the v2 adapter produces 80. The answer is correct and too short for the task. A coding prompt shows the same pattern (751 versus 1,425 characters). The concision that is a virtue in prose becomes a defect in assistance: the model learned to cut ornament so well that it cut substance.
The fix is not retraining. It is a single instruction added to the server-side persona: when the task calls for code, math, step-by-step, or technical explanation, be complete and do not sacrifice completeness for concision. Re-running the identical benchmark with this instruction recovers the model to parity or a win.
| Judge | Win | Tie | Loss | v2 win rate |
|---|---|---|---|---|
| GLM | 10 | 9 | 5 | 41% |
| Codex | 15 | 8 | 1 | 62% |
Concision remains available for prose; completeness returns for the tasks that demand it. This mitigation is deployed in production.
7. Discussion
Five lessons generalize beyond this project.
The format of the data is what is learned. The single change that turned a regression into a win was the format of the training pair, from {theme, article} to {question, answer}, with no change in source material or training budget. If you show a model call transcripts formatted one way, that format is what comes out, whatever the content.
Measure before celebrating. A model trained on your data can be worse than the base, and it fails silently. Without a promotion gate built before training, you ship the regression believing it is an improvement. The v1 adapter would have shipped on intuition.
Separate the axes. Voice, reasoning, and usefulness moved up, flat, and down respectively in the same training run. Measuring only the axis you hope to improve produces confident, wrong conclusions from real numbers.
Try the prompt before retraining. A large fraction of what looks like a training defect is an instruction defect, and instructions are cheap, reversible, and testable in minutes. We nearly launched a third training run before discovering a one-sentence prompt resolved the regression.
A small fine-tune gives voice, not capability. If the goal is a more capable model, fine-tuning a small model on your own text is the wrong lever, and no amount of style data fixes it. The real gain of this project fits in one sentence: the model came to sound like the author without losing what it already knew, once we stopped celebrating and started measuring.
8. Limitations
The conclusions are bounded by the evaluation. The MT-Bench-PT set is small (24 conversations) and is a custom set, not the official MT-Bench nor a public Portuguese leaderboard, so the absolute conversation numbers are indicative rather than comparable. The judges are LLMs and inherit their biases, partially mitigated by blind randomized ordering and two independent judges. ENEM is scored zero-shot by final-token log-likelihood, which measures answer selection rather than free-form reasoning. Results come from single training and evaluation runs without variance estimates. The persona and safety layer live in the serving prompt rather than the weights, which is a deployment choice that keeps them auditable and editable but means the served behavior is the model plus its prompt, not the adapter alone. Finally, the corpus is one author in Portuguese; the pipeline should transfer, but the numbers are specific to this voice.
9. Reproducibility and Artifacts
All code and artifacts are public or available on request.
Code (huggingface.co/guifav/caramelo):
- Dataset pipeline:
finetune/dataset_v2/(gen_prompts.py,gemma_draft.py,prep_batches.py,merge_corrected.py,markers-basedfilter_assemble.py,train_v2.py,RUBRIC.md). - Style evaluation:
eval/run_eval.py,eval/judge.py,eval/markers.py. - Capability benchmarks:
eval/bench/bench_enem.py,eval/bench/run_mtbench.py,eval/bench/judge_mtbench.py,eval/bench/mtbench_pt.jsonl. - Serving:
gateway/(FastAPI, OpenAI-compatible, server-side persona and safety injection), CLIcaramelo(npm).
Models and data (Hugging Face):
guifav/caramelo-lora-adapter(v1),guifav/caramelo-lora-adapter-v2(v2 adapter),guifav/caramelo(merged model),guifav/caramelo-v2-data(dataset bus),guifav/caramelo-eval(evaluation outputs).
Training configuration: base google/gemma-3-4b-it; QLoRA 4-bit NF4; rank 16, alpha 32, dropout 0.05; LR 2e-4, warmup 0.03; 3 epochs; effective batch 16; max length 2048. Generation and training ran on Hugging Face Jobs (L4 GPU) with a Hugging Face Dataset as the inter-stage bus.
10. Conclusion
Caramelo is a small result stated plainly: a 4-billion-parameter open model now answers in one author's voice, with reasoning intact, after a first attempt that made it worse. The method that fixed it is a style-correction dataset whose pairs match the inference task, filtered by objective markers, and the discipline that made the result trustworthy is an evaluation gate built before training and read across three independent axes. The open question that motivated the project remains worth asking of any customized model in production: how many are weaker than the base they replaced, simply because no one built the gate to find out?
References
- Hu, E. et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685.
- Dettmers, T. et al. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314.
- Zheng, L. et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. arXiv:2306.05685.
- McCloskey, M. and Cohen, N. (1989). Catastrophic Interference in Connectionist Networks. Psychology of Learning and Motivation, 24.
- Goodfellow, I. et al. (2013). An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks. arXiv:1312.6211.
- Google DeepMind (2025). Gemma 3 Technical Report.
Appendix A. Style rubric (summary)
The rubric given to the rewriting subagents asks for: a short opening that answers immediately; real data, examples, or studies; rhythmic variation between short and long sentences; operational analogies; numbered enumeration where useful; natural Brazilian Portuguese. It explicitly forbids the em-dash inside a sentence and the negation-correction construction ("not X, but Y"), the two markers the author identifies as typical of AI-generated text.
Appendix B. Production persona and safety
The served model is the merged adapter plus a server-side system prompt that sets the voice, the completeness instruction from Section 6.3, an identity anchor (the model is Caramelo, based on Gemma 3 4B, with its manner of speaking trained by the author, and is not Gemini, GPT, or OpenAI), and a safety layer (anti-hype, anti-prompt-extraction, crisis referral). Keeping these in the prompt rather than the weights keeps them auditable and revisable without retraining, at the cost of coupling served behavior to the prompt.